A Link to my MSc Thesis
October 6, 2019
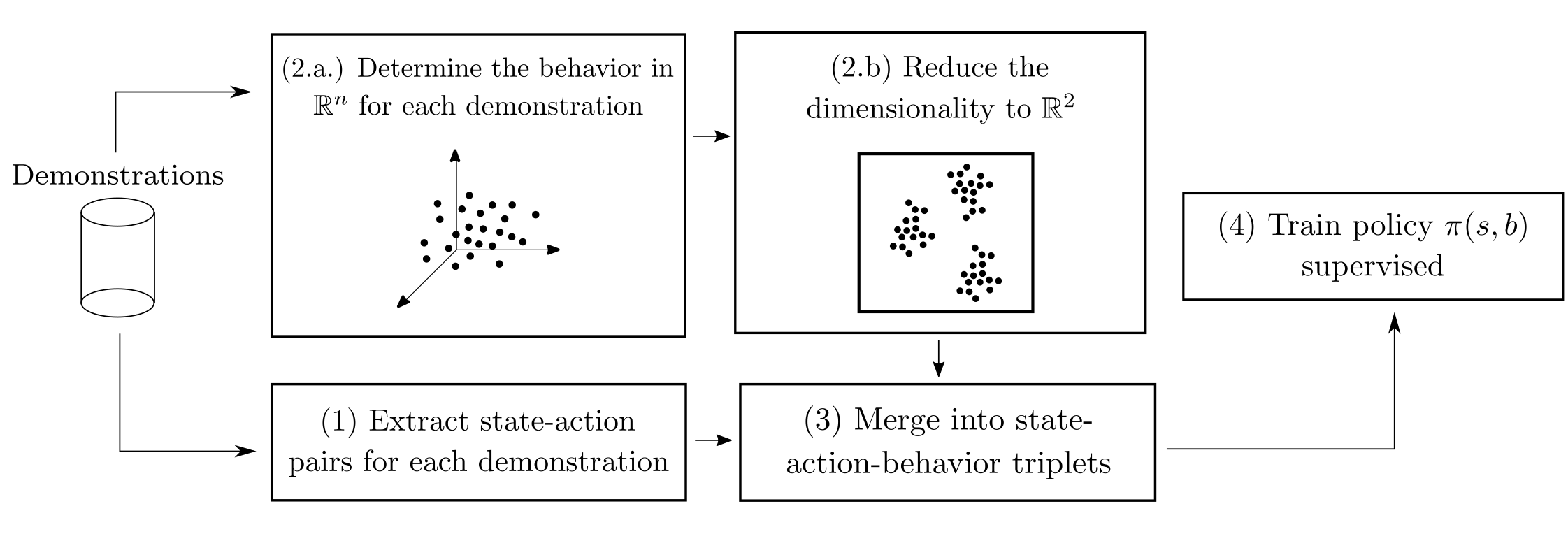
The title of this post is the title of my M.Sc. thesis, which I defended on Friday 27th, 2019. In this thesis I explore a method deviced by Niels Justesen, Sebastian Risi and I, called Behavioral Repertoires Imitation Learning. This method extends Imitation Learning by adding behavioral features to state-action pairs. The policies that are trained with this method are able to express more than one behavior (e.g. bio-oriented, mech-oriented) on command.
In summary, the way this is done is by designing a behavior space, a subset of \(\mathbb{R}^M\) that encodes the player’s behavior in some way. After that, the dimensions are reduced in order to clusterize and understand the different behaviors present in the demonstrations. Finally, we expanded the state-action pairs gathered from the demonstrations with the coordinates in this low-dimensional space. This process was originally described in this preprint on arXiv. The behavior space I tackled in my thesis was a little bit different.

Last week, I pushed the final document of my thesis to the public repositories of the National University of Colombia. Here’s a link to it.